
如果想問問題或單純回饋的話可以填寫表單唷
在機器學習當中,如果特徵數過多時,有可能會造成一些問題,像是:
- 過擬合 (overfitting)
- 處理速度較慢
- 如果超過三個特徵以上不好視覺化
所以這時候就需要對特徵做降維,在實務上,一個幾百幾千個的特徵當中,手動挑選特徵顯然不是一個明智的方法,所以以下來介紹兩個在機器學習中常常使用的兩種降維方法。
PCA(principal component analysis)主成份分析
在介紹 PCA 之前,我們先來定義一下我們的目標是什麼:
將一個具有 n 個特徵空間的樣本,轉換為具有 k 個特徵空間的樣本,其中 k < n
以下是 PCA 的主要步驟:
- 將數據標準化
- 建立共變異數矩陣(covariance matrix)
- 利用奇異值分解(SVD)求得特徵向量(eigenvector)跟特徵值(eigenvalue)
- 通常特徵值會由大到小排列,選取 k 個特徵值與特徵向量
- 將原本的數據投影(映射)到特徵向量上,得到新的特徵數
PCA 最重要的部分就是奇異值分解,因此接下來的章節讓我們來談談奇異值分解
直觀理解奇異值分解
在矩陣分解當中,奇異值分解是個相當有名的方法。矩陣分解在高中數學當中最常見的用途就是解方程式(如 LU 分解),從奇異值分解的公式當中我們可以直觀地了解:
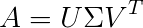
其中 A 為一個 m x n 的矩陣,𝑈 跟 V 都為正交矩陣,𝛴 為奇異值矩陣。奇異值矩陣為矩陣 A 對應的特徵值,在 PCA 當中又叫做主成份,代表對保存訊息的重要程度,通常由大到小遞減排列在對角中,是個對稱矩陣。
那麼這邊的 A 對應什麼呢?當然就是我們的特徵,只是特別要注意的是這邊的 A 我們通常使用**共變異數矩陣(covariance martix)**來求算,記得資料一定要先正規化後在進行奇異值分解
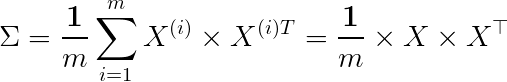
共變異數矩陣(covariance matrix)
因為共變異數矩陣常用 Sigma 表示,不要跟上面的 𝛴 搞混囉。因此如果要降維,我們可以用 U 的前 k 列乘上對應 𝛴 當中的特徵向量,就可以得出新的特徵了,而從幾何的角度來看
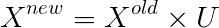
這樣子的運算在幾何當中,其實是將 X 投影到 U 的前 k 個向量
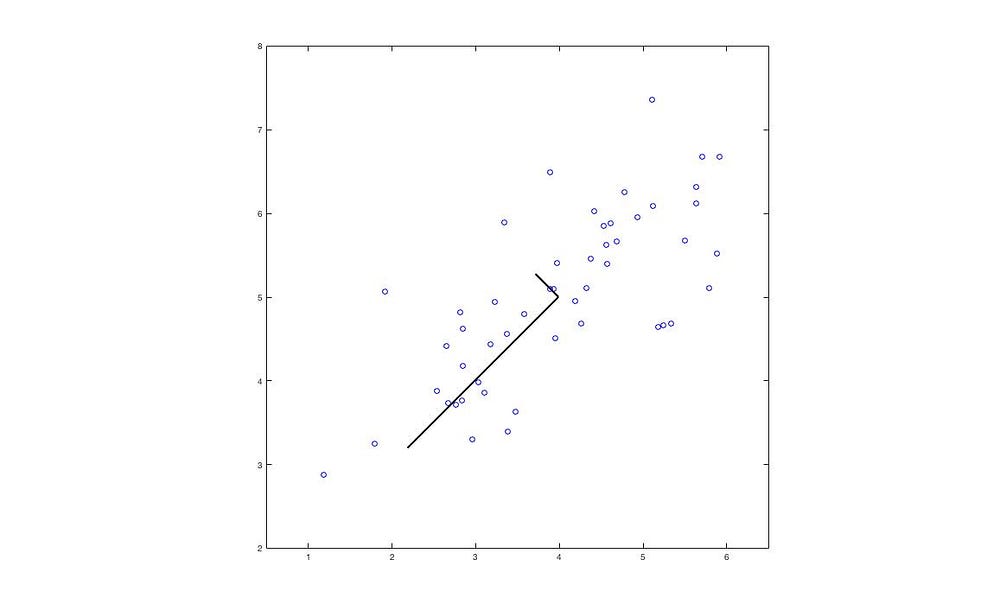
當中的黑線為特徵向量,長度為特徵值。
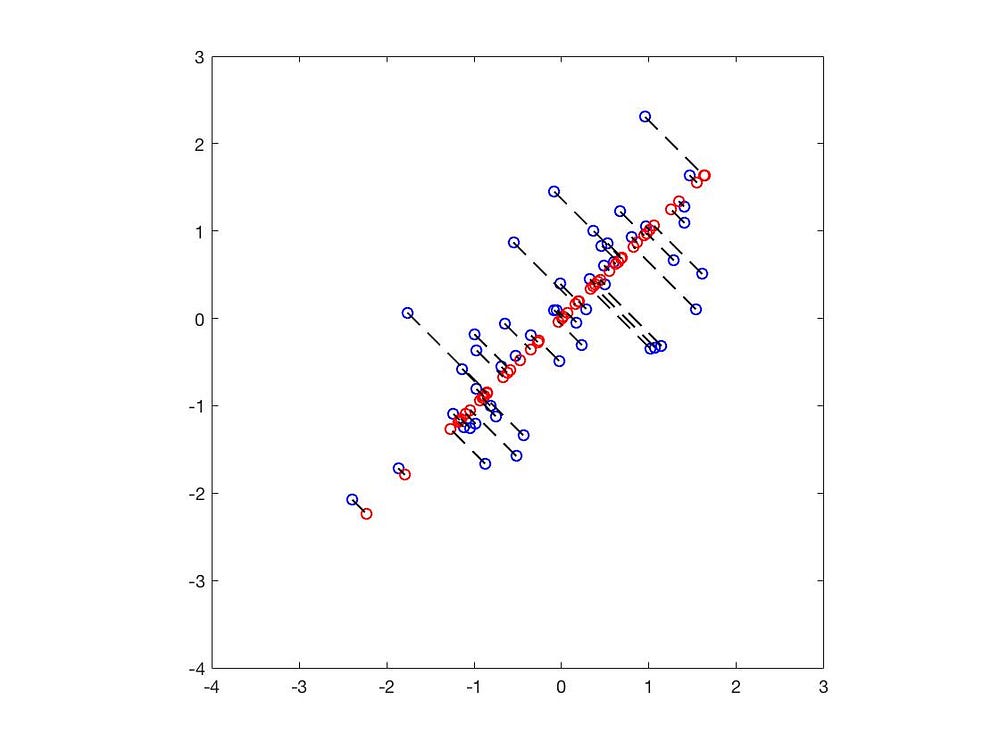
當中的藍點為數據原本的位置,紅點則是投影到特徵向量的位置。以上,我們成功將 2 維的數據降至一維了。
當然也可以從 3 維降到 2 維:
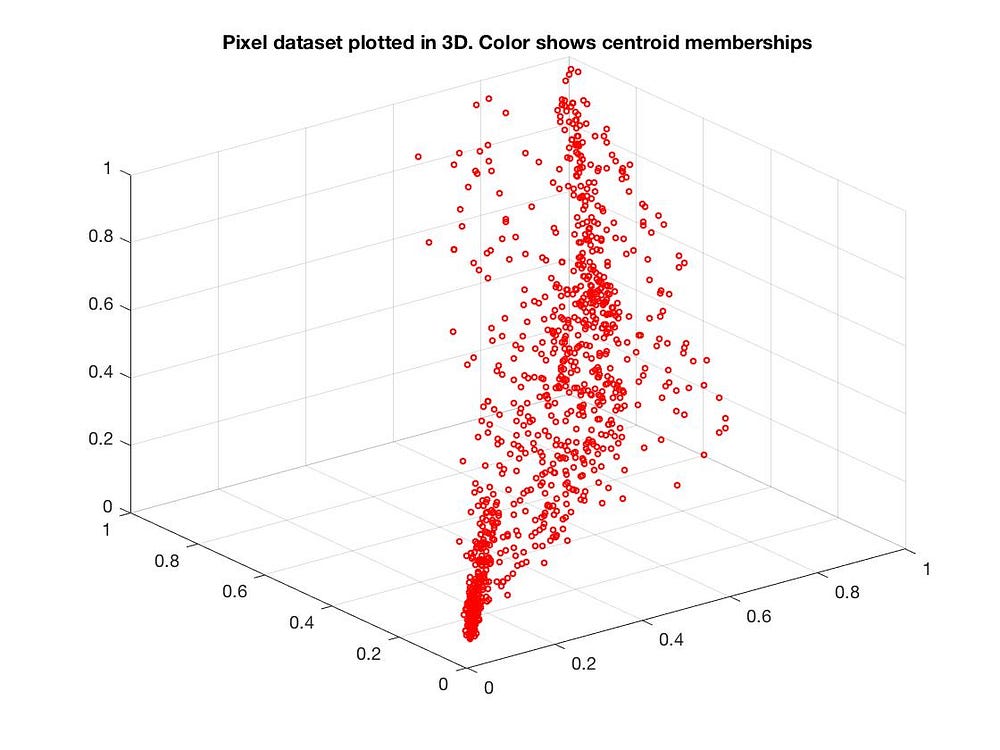
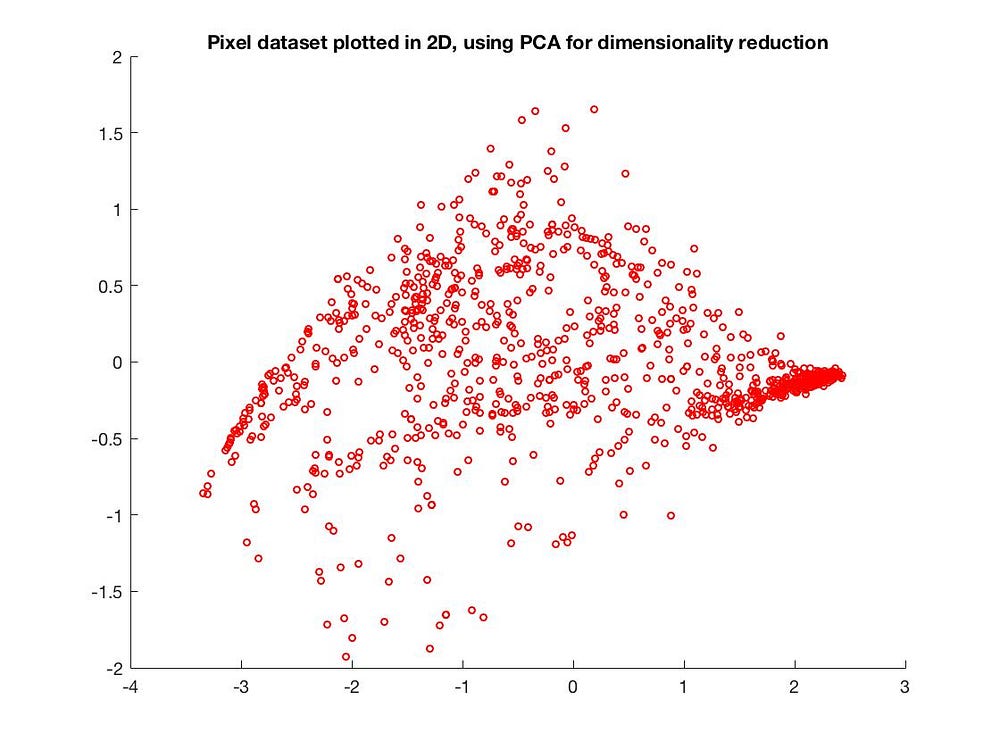
PCA 的應用
在降維的時候,我們希望留下最重要的特徵,剩下的比較不重要的特徵我們直接捨棄掉。
像是判斷一個人時,最重要的判別方式可能就是眼睛、鼻子、嘴巴等等,所以膚色、頭髮等等的特徵我們就可以捨棄,事實上在人臉辨識當中也常利用 PCA 做降維。

這是對奇異值分解相當直觀的了解,篇幅關係無法深入細談,若對奇異值分解有興趣可自行到維基百科
t-SNE
PCA 是個相當直觀且有效的降維方式,不過在三維轉換為二維時我們可以看到,有些數據的集群完全被搗成一團。
PCA 是一種線性降維的方式,但如果特徵與特徵間的關聯是非線性關係的話,用 PCA 可能會導致欠擬合(underfitting)
t-SNE 也是一種降維方式,不過他用了更複雜的公式來表達高維與低維之間的關係。t-SNE 主要是將高維的數據用高斯分佈的機率密度函數近似,而低維數據的部分使用 t 分佈的方式來近似,在使用 KL 距離計算相似度,最後再以梯度下降(或隨機梯度下降)求最佳解 。
高斯分佈的機率密度函數
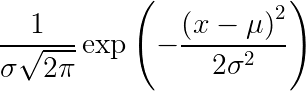
其中,X 為隨機變量,𝝈 為變異數,𝜇 為平均。
因此原本高維的數據可以這樣表示:
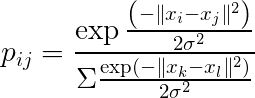
而低維的數據用 t 分布的機率密度函數可以這樣表示(自由度為 1)
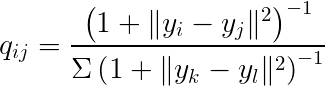
其中,x 為高維當中的數據,y 為低維當中的數據。P, Q 分別代表機率分佈。
為什麼會使用 t 分佈來近似低維的數據呢?主要是因為轉換成低維之後一定會丟失許多訊息,所以為了不被異常值影響可以使用 t 分佈。
t 分佈在樣本數較少時,可以比較好模擬母體分布的情形,不容易被異常值所影響。
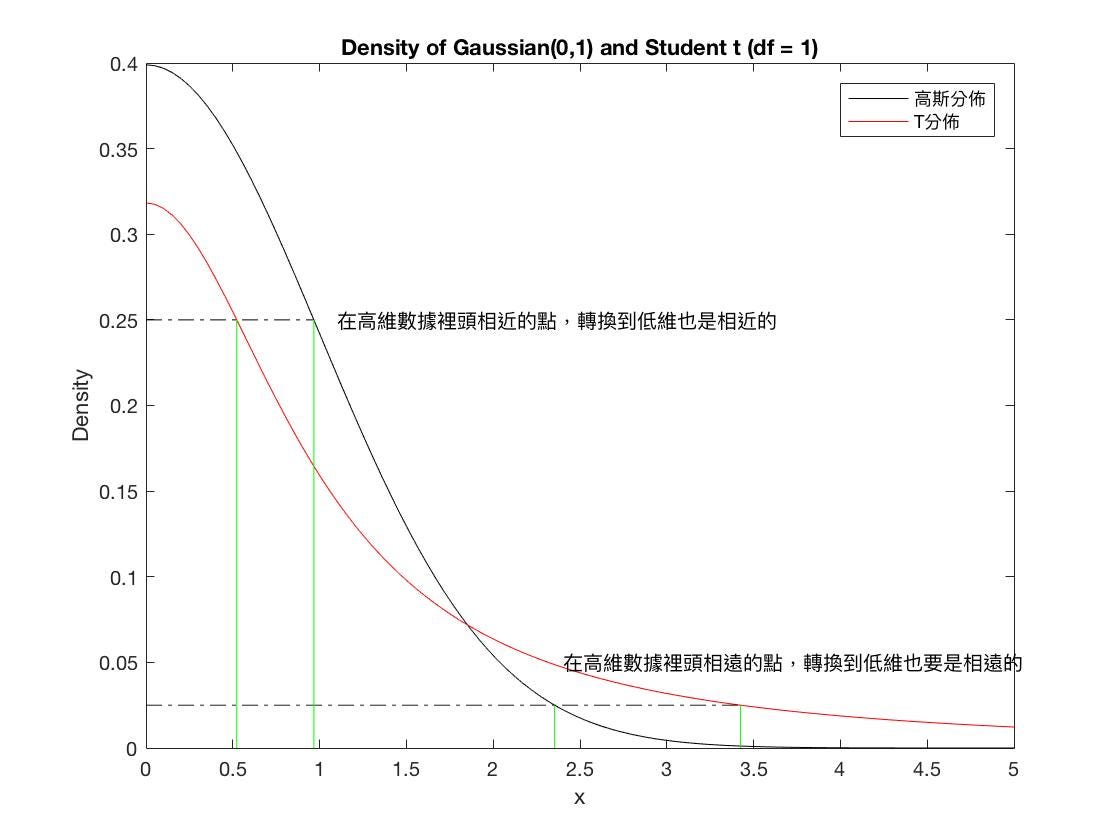 T 分佈與高斯分佈的機率密度函數
T 分佈與高斯分佈的機率密度函數
兩個分佈之間的相似度
求算兩個分佈之間的相似度,經常用 KL 距離(Kullback-Leibler Divergence)來表示,也叫做相對熵(Relative Entropy)。
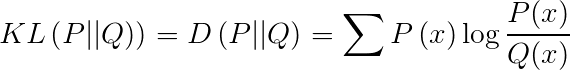
在 t-SNE 中使用了困惑度(Perp)來當作超參數。
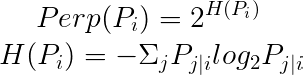
論文中提出通常困惑度在 5 ~ 50 之間。
Cost function
用 KL 距離計算 Cost
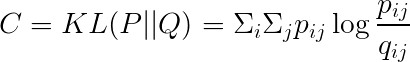
求梯度可以寫成
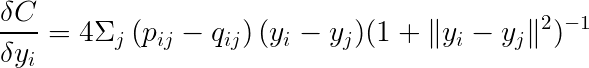
最後再利用梯度下降法(或隨機梯度下降法)就可以找到最小值了。
實測:使用 MNIST 測試
測試集可以到這裡下載,首先我們先用 PCA 降到二維看看。
PCA
 PCA 降維
PCA 降維
可以發現降到二維之後,資料幾乎被搗成一團,完全看不出集群,這是因為 PCA 的線性降維在過程中損失太多訊息。
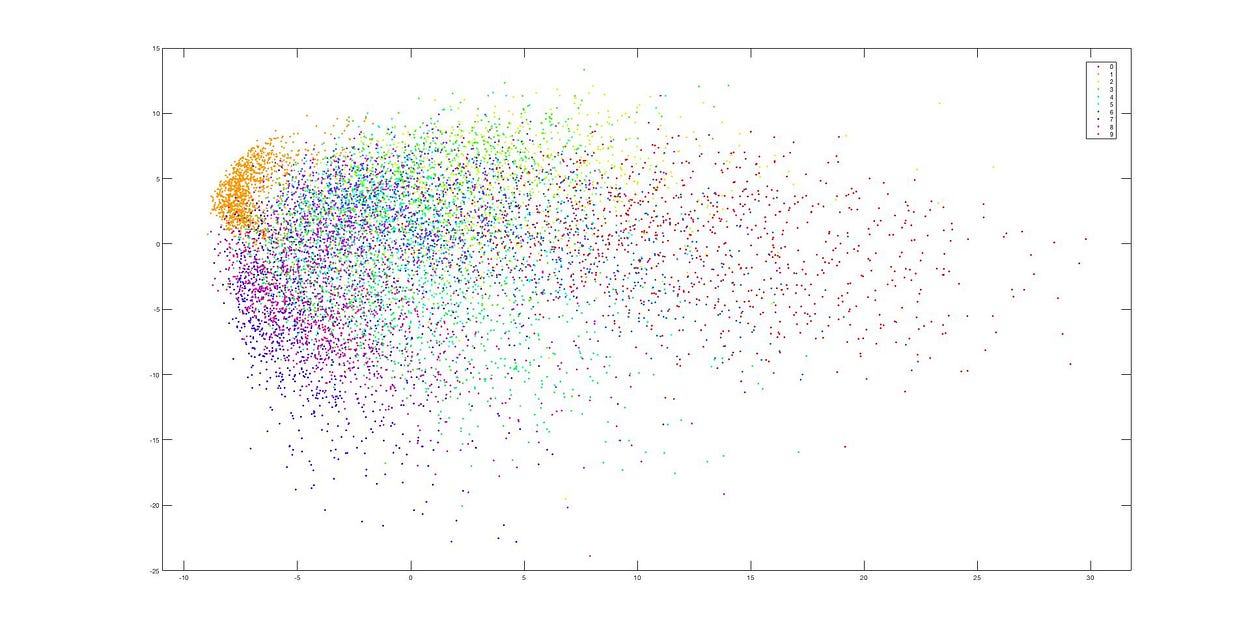
t-SNE
接下來使用 t-SNE 測試
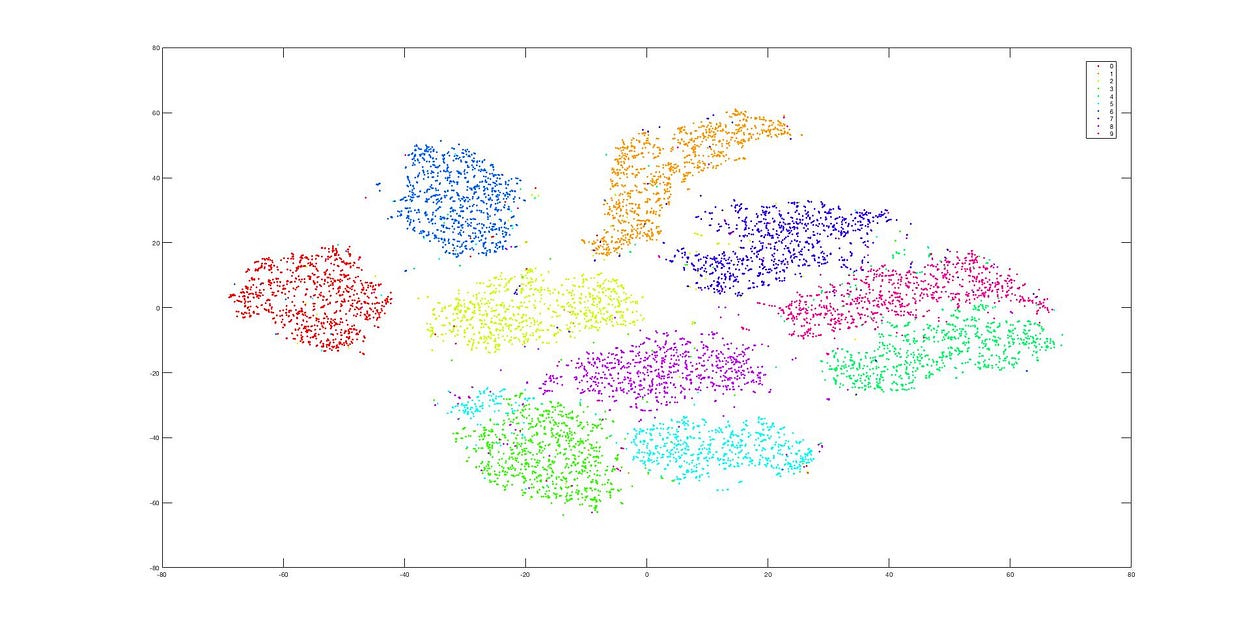 使用 t-SNE 降維
使用 t-SNE 降維
這是使用 t-SNE 後的降維結果,可以發現降維過後,資料仍然分群地相當明確。從這兩張圖可以非常明顯看出這兩者(PCA, t-SNE)的差別。
小結
後來又有人提出一連串改善 t-SNE 效能的演算法,詳情可以參考Accelerating t-sne using tree-based algorithms,大部分熱門的資料分析程式語言也都有實作,像是 sklearn, R, matlab 等等。
不過畢竟** t-SNE 不是線性降維,在執行時間上會比 PCA 來得久許多。**
- 當特徵數量過多時,使用 PCA 可能會造成降維後的特徵欠擬合(underfitting),這時可以考慮使用 t-SNE 來降維
- t-SNE 的需要比較多的時間執行
- 論文當中還有一些優化技巧(如何選擇困惑度等等),因為還沒有閱讀完畢,之後會再逐漸補上
參考資料
- Van der Maaten L, Hinton G. Visualizing data using t-SNE
- Accelerating t-sne using tree-based algorithms 利用各種樹的演算法來加速 t-SNE 的運算
- 線代啟示錄 - 奇異值分解
文章同步發表於 medium
如果覺得這篇文章對你有幫助的話,可以考慮下面的連結請我喝一杯 ☕ 可以讓我平凡的一天變得閃閃發光 ✨
☕Buy me a coffee