カンマに数字を追加する正規表現の説明
# フロントエンド一般に通貨を表示する際には、元の数字を人間が理解しやすい形式に変換する必要があります。例えば:
- 1234567 → 1,234,567
- 10000 → 10,000
フロントエンドでは、以下のような方法で実現できます:
Intl.NumberFormatを使用する(古いブラウザではサポートされていない場合があるため、polyfillが必要です)- 正規表現と
.replaceを組み合わせる
この問題に関しては、StackOverflowで多くの議論がありますが、最も人気のあるものはこの投稿でしょう:How to print a number with commas as thousands separators in JavaScript
解答には様々なものがありますが、全体的な形は主にこの2つです:
const reg1 = /\B(?=(\d{3})+$)/
const reg2 = /(\d)(?=(\d{3})+$)/この記事では、これら2つの正規表現の違いと実際の実行方法について説明します。最後にパフォーマンスも実際に測定します。
前言
始める前に、いくつかの重要な概念を理解しておく必要があります:positive lookahead、negative lookahead、および word boundary。これは一般的に正規表現を学ぶ際にあまり触れられないが、実際には非常に強力な概念です。
Positive lookahead と Negative Lookahead
正規表現において、positive lookaheadは ?= という記号で表されます。例えば a(?=b) と解釈すると、この正規表現は、次の文字が b である a を一致させることを意味します。ここで特に注意すべきは、?= 本体は一致しないため、この正規表現は a のみ一致するということです。
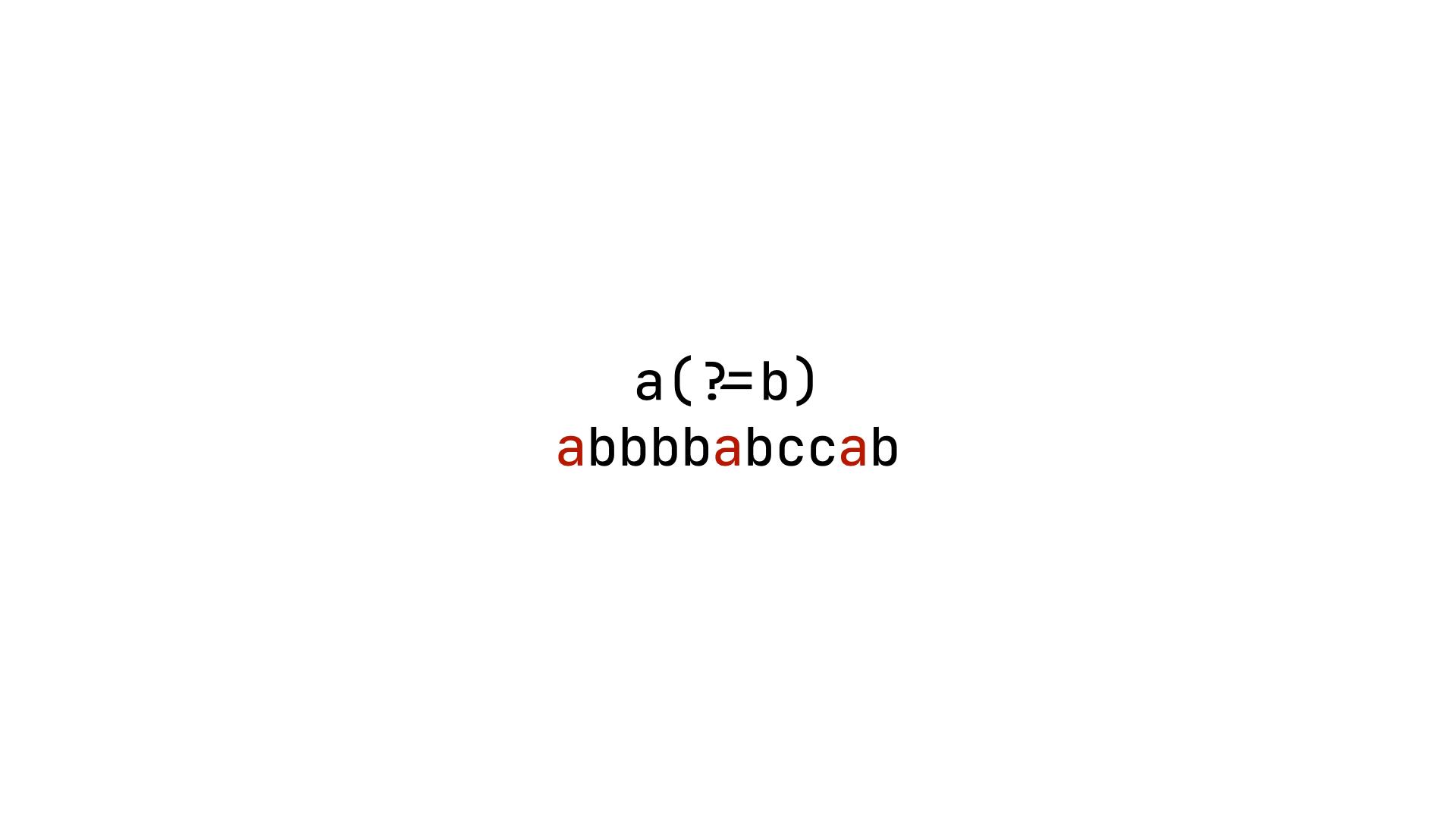
上記の図からもわかるように、この正規表現で一致するのは a のみです。
文字だけでなく、lookaheadの構文は任意の有効な正規表現を受け入れることもできます。例えば:,(?=(?:\d{3})+$) という正規表現は、後ろに3つ連続した数字が続く位置に一致し、1回以上繰り返され、ちょうど結末に一致する , を意味します。

negative lookaheadは ?! で表され、positiveの反対です。例えば a(?!b) は、次の文字が b でない a を一致させます。
特に注意すべきは、positive lookahead と negative lookahead はどちらも zero-length の表現であり、つまり彼らは自身で何の文字も一致させないため、その長さは 0 です。これはちょうどアンカーのようなものです。もし (?=a) の後に何の文字も加えなければ、以下のような結果になります:

一致は成功したものの、長さは 0 であることがわかります。
最初の正規表現:
/\B(?=(\d{3})+$)/ と /(?=(\d{3})+$)/ は意味はほぼ同じです(いくつかの部分に違いはあります)。なぜこの2つの表現が同じなのかについては、次に \b と \B の説明をします。
\b と \B の意味
\b
正規表現の大文字と小文字は通常、正と負の意味を表します。例えば \d は数字に一致し、 \D は数字でないものに一致します。まず、 \b の意味を理解しましょう。これは MDN のドキュメント を参考にしています:
A word boundary matches the position where a word character is not followed or preceded by another word-character. Note that a matched word boundary is not included in the match. In other words, the length of a matched word boundary is zero.
次に、word character がどのように定義されるかを理解するために、 \w を見てみましょう。\w は以下のように定義されています:
数字、アルファベット、アンダースコアを含み、
[A-Za-z0-9_]と等しい。
\w が何であるかを理解した後、文中の word character is not followed or preceded by another word-character の意味を見てみましょう。 \b は以下のような状況で現れます。混乱を避けるため、ここでは word character を \w と表現します。
- word character の開始部分
- word character と非 word character の間
- word character の終了部分
図で見た方がわかりやすいでしょう:

実際には、word boundary の概念を使って理解することができます。つまり、文字と文字の間の場所です。ただし、特に強調したいのは、他の文字を追加しない場合、\b 自体はゼロ幅一致であり、したがって一致の長さはすべて 0 ですが、一致がないわけではありません。
また、文字があるときに混同しないようにしましょう。例えば d\b は、文字 d の後に word boundary が存在する文字を一致させることを意味します。この場合、実際に一致する文字は d になります:

\B
\B は逆の意味を持ち、非 word boundary の部分を示します。非 word boundary とは何か?上の図で矢印がない部分です。

正規表現の正しい解析方法
正規表現を理解するには、経験の蓄積が必要です。ただし、開発で使用されるものに関しては、いくつかの概念を持っておくと良いでしょう。正規表現は状態機械の遷移として見ることができます。例えば \d+ は以下のように表現できます:

一般には初期状態を加える必要があるかもしれません(例えば、非数字が入力された場合、状態 0 に到達すべきではないなど)。ただし、理解できれば問題ありません。矢印の中に可能な入力文字を配置し、次の状態に遷移するかどうかを判断します。状態が終端状態である場合、これは一致が受け入れられたことを意味します。

表現の解析を開始する
方法 1:ゼロ幅の特性を利用した一致
前提知識と必要な知識の説明が終わったので、ついに分析を始めることができます。まず、最初のものを見てみましょう:/\B(?=(\d{3})+$)/g
最初の \B は非 word boundary の位置に一致します。次に (?=) の後の正規表現を見てみましょう。(\d{3})+ は連続する3つの数字に1回以上一致することを示し、例えば 333、666、123 などです。次に (?!) の後の正規表現を見てみると、\d は1つの数字に一致します。これをすべて繋げると、(1つの数字の前が3つの連続した数字でないことに一致し、1回以上の非 word boundary) という意味になります。
ここで面白いのは、後ろの (\d{3})+$) の部分です。この正規表現は、一致する結果の長さが必ず3の倍数であり、ちょうど結末であることを意味します。例えば、123456 は3の倍数の長さですが、12345 は \d{3} に一致しても、結末でないため一致とは見なされません。
この特性を利用し、\B の巧妙な適用により、数字 1000000 の場合、最後には2つの位置が一致します。

したがって、.replace を呼び出すときは、次のように書けます:
"1000000".replace(/\B(?=(\d{3})+$)/g, ",");上の図の一致結果に基づいて、これら2つの位置に , が挿入され、1,000,000 になります。これが、この正規表現が $1, を必要としない理由です。なぜなら、\B と (?=) はどちらもゼロ幅の一致であり、一致の長さは 0 だからです。
一致のプロセスは、以下の動画で観察できます。この一致回数は参考値に過ぎず、言語によって異なる状況があるかもしれません。同時にいくつかのステップを省略していますが、全体的な流れはだいたいこのようになります:
方法 2:カンマを挿入すべき数字を一致させる
/(\d)(?=(\d{3})+$)/
ここからわかるのは、\B が削除され、\d が追加された以外は、全体的にはあまり変わらないということです。しかし、ここで異なる点は、\d が実際に数字に一致することです。最終的な結果は次のようになります:

(画像中に ?: を追加して、結果をグループに入れないことを示していますが、結果は同じです)
私は、グループに入れられた値を使用しない場合は、?: を使って表現するのが習慣です。これは他の人や未来の自分が理解しやすくなります。
全体のプロセスはこのようになります:(中間の一致失敗のプロセスは省略)
したがって、JavaScriptでは次のように書きます:
"1000000".replace(/(\d)(?=(\d{3})+$)/g, "$1,"); // 注意:ここでの $1この $1 は非常に重要です。なぜなら、一致した文字も一緒に入れなければならず、 , だけだとこうなってしまいます:,00,000。
その他の考慮事項と方法
上記の2つの正規表現は、(?=(\d{3})+$) を一致の条件として使用していますが、実際には小数点が出現することもあります。この場合、1000.12 のようにうまく一致しない可能性があります。
この場合、正規表現を修正して小数点の出現に対応する必要があるかもしれません。例えば、 \b を追加して word boundary を作り、一致が小数点で停止するようにします。
さらに、ブラウザのAPIは Intl.NumberFormat をサポートしており、すぐに使用できます。使用方法は MDN のドキュメント を参照してください。
new Intl.NumberFormat('ja-JP', { style: 'currency', currency: 'JPY' }).format(number);パフォーマンスとその他の考え
結果が同じであれば、考慮すべき点は可読性とパフォーマンスの2つだけです。
可読性、使いやすさの観点から言えば、最も良いのは Intl.NumberFormat です。MDN のドキュメントは非常に明確に書かれており、とても使いやすいです。
唯一の注意点は、パフォーマンスです。ここで jsbench を使用して テスト を行いました。Intl.NumberFormat のパフォーマンスはほぼ倍遅くなっていることがわかります。私は、i18n の読み込みや各国の数字変換が大きなスペースを必要とするのだろうと推測しています。

また、ゼロ幅一致を使用する方が \d を使用するよりも半分早いです。これはゼロ幅の特性によるものでしょう。しかし、(\d{3})+ のような表現では、+ がある限り、backtracking の方法で一致が行われるため、できるだけ多くの結果を一致させようとします。したがって、.+123 のような表現では、できるだけ多くの結果を一致させ、成功しない場合に前に戻ります。大量の backtracking は正規表現のパフォーマンス問題を引き起こす可能性があるため、類似の表現を使用する際は特に注意が必要です。
実務では、requestIdleCallback の方法を利用して、Intl.NumberFormat の初期化を遅延させ、過度のパフォーマンス影響を避けることができます。または、追加の関数を書いてロジックを包み、他のファイルから本当に呼び出された後に初期化することもできます。これにより、パフォーマンスの問題を回避できるでしょう。
その他の方法
上記の正規表現は、主に lookahead に基づいて構築されていますが、自分でループを作成する場合、どのように行うことができますか?ここでは /(\d)(?=(?:\d{3})+\b)/g を次のように書き換えました:
let digits = number.toFixed(2).toString()
let matcher = /(\d)(?=(?:\d{3})+\b)/g
while (matcher.test(digits)) {
let first = digits.slice(0, matcher.lastIndex);
let second = digits.slice(matcher.lastIndex);
digits = first + "," + second
}また、さらに直感的な方法として、一度の実行で一度変更する方法もあります:
let digits = number.toFixed(2).toString()
let matcher = /(\d+)(\d{3})/
while (matcher.test(digits)) {
digits = digits.replace(matcher, "$1,$2");
}再度結果を見てみましょう:
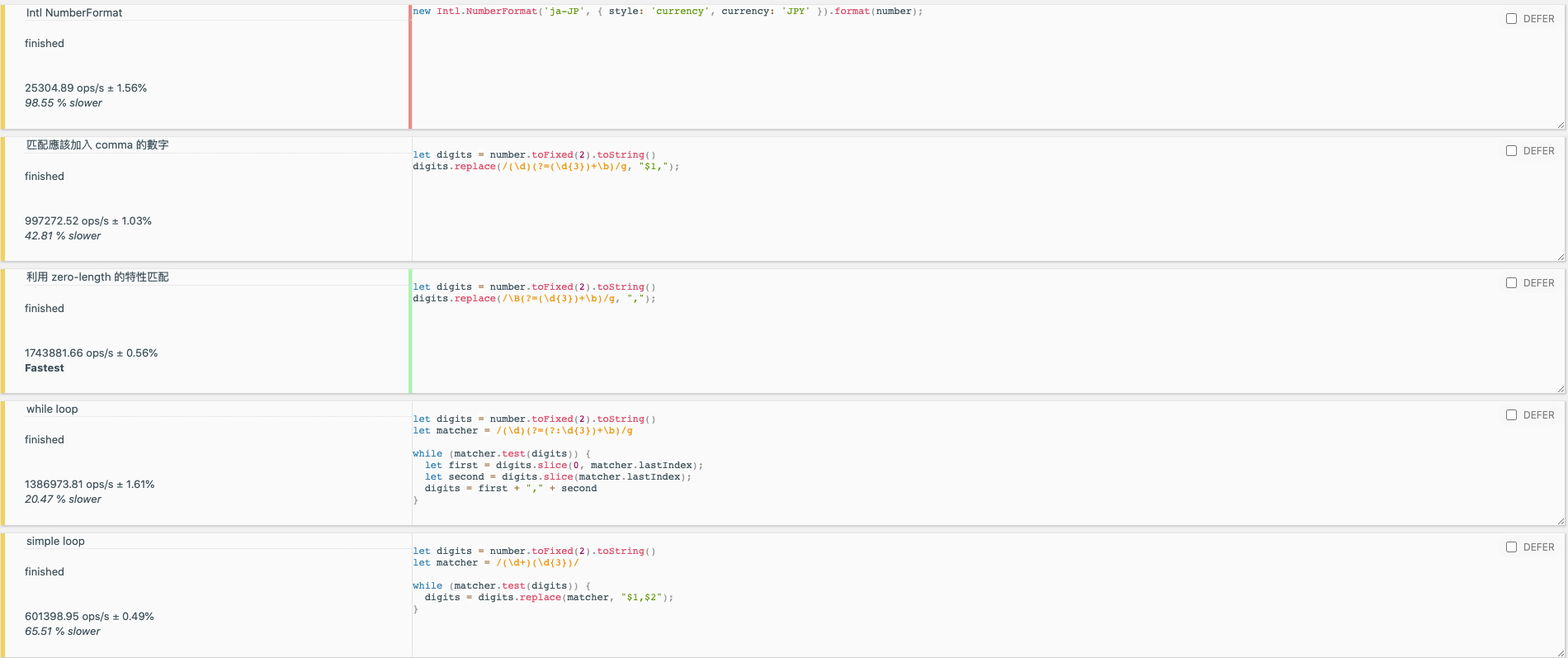
| 名前 | Ops/s | |
|---|---|---|
ゼロ幅の /\B(?=(\d{3})+\b)/g | 1778943 ops/s 最速 | |
| ゼロ幅の特性を利用した一致 (without \B) | 1712701 ops/s 3.72% 遅い | |
| while ループ | 1371453 ops/s 22.91% 遅い | |
| シンプルなループ | 597173.88 ops/s 66.43% 遅い | |
Intl.NumberFormat | 25304.89 ops/s 98.55% 遅い |
最速なのは依然として zero-length を用いた一致の方法で、その次が while-loop、最も遅いのは Intl.NumberFormat です。テスト結果に興味がある方は、こちらのリンクで試してみてください。
後記
正規表現には語るべきことがたくさんありますが、lookahead や word boundary は比較的あまり取り上げられない概念です。ここで一度整理しておきました。多くの概念が MDN の文書に詳細に記載されており、Regex101 というサイトを利用すると、正規表現を視覚化でき、横に詳細な説明があり非常に便利です。
とはいえ、正規表現は便利で使いやすいものの、本当に理解するのは難しいと思います。
関連リソース
関連記事
- フロントエンドで画像を使うときに注意すべきことJake Archibald の記事をもとに、現代的なレスポンシブ画像の書き方を整理する。なぜ width/height は今でも必要なのか、CSS の aspect-ratio はいつ使うのか、AVIF と WebP をどう選ぶのか、そして picture/source/srcset でモバイル向け画像を切り替える方法までまとめる。
- CSS field-sizing — 1行のCSSでフォーム要素を自動リサイズさせるtextarea の自動高さ調整は、以前は scrollHeight を監視する JavaScript が必要だった。CSS field-sizing: content なら1行で済む。textarea・input・select に対応。
- 超リンクの下線をもっときれいに見せる:text-underline-offsetデフォルトでは下線が文字にかなり近く、こういう見た目を好まないデザイナーもいる。僕自身も、あまりきれいだとは思っていない。
- なぜウェブは Pixel Perfect を追求すべきではないのかPixel Perfect が本当に重要なときだけそれを気にすべきであり、そうでなければ往々にして双方にとって損な結果になる。