Explanation of regular expression to add a number to comma
# FrontendWhen displaying currency, there is often a requirement to convert raw numbers into a more human-readable format. For example:
- 1234567 → 1,234,567
- 10000 → 10,000
In frontend development, there are several ways to achieve this:
- Using
Intl.NumberFormat(may require a polyfill for older browsers) - Utilizing regular expressions with
.replace
This topic has been widely discussed on StackOverflow, with one of the most popular threads being: How to print a number with commas as thousands separators in JavaScript
There are many solutions available, but they generally revolve around these two regular expressions:
const reg1 = /\B(?=(\d{3})+$)/
const reg2 = /(\d)(?=(\d{3})+$)/This article aims to explain the differences between these two regular expressions and how they function in practice. Lastly, we will evaluate their performance.
Introduction
Before we dive in, there are some important concepts to understand: positive lookahead, negative lookahead, and word boundary. These are not commonly encountered when learning regular expressions, but they are quite powerful concepts.
Positive Lookahead and Negative Lookahead
In regular expressions, positive lookahead is denoted by ?=. For instance, a(?=b) means that the expression will match a only when it is followed by b. It is crucial to note that ?= itself does not match any characters; thus, this expression will only match a.
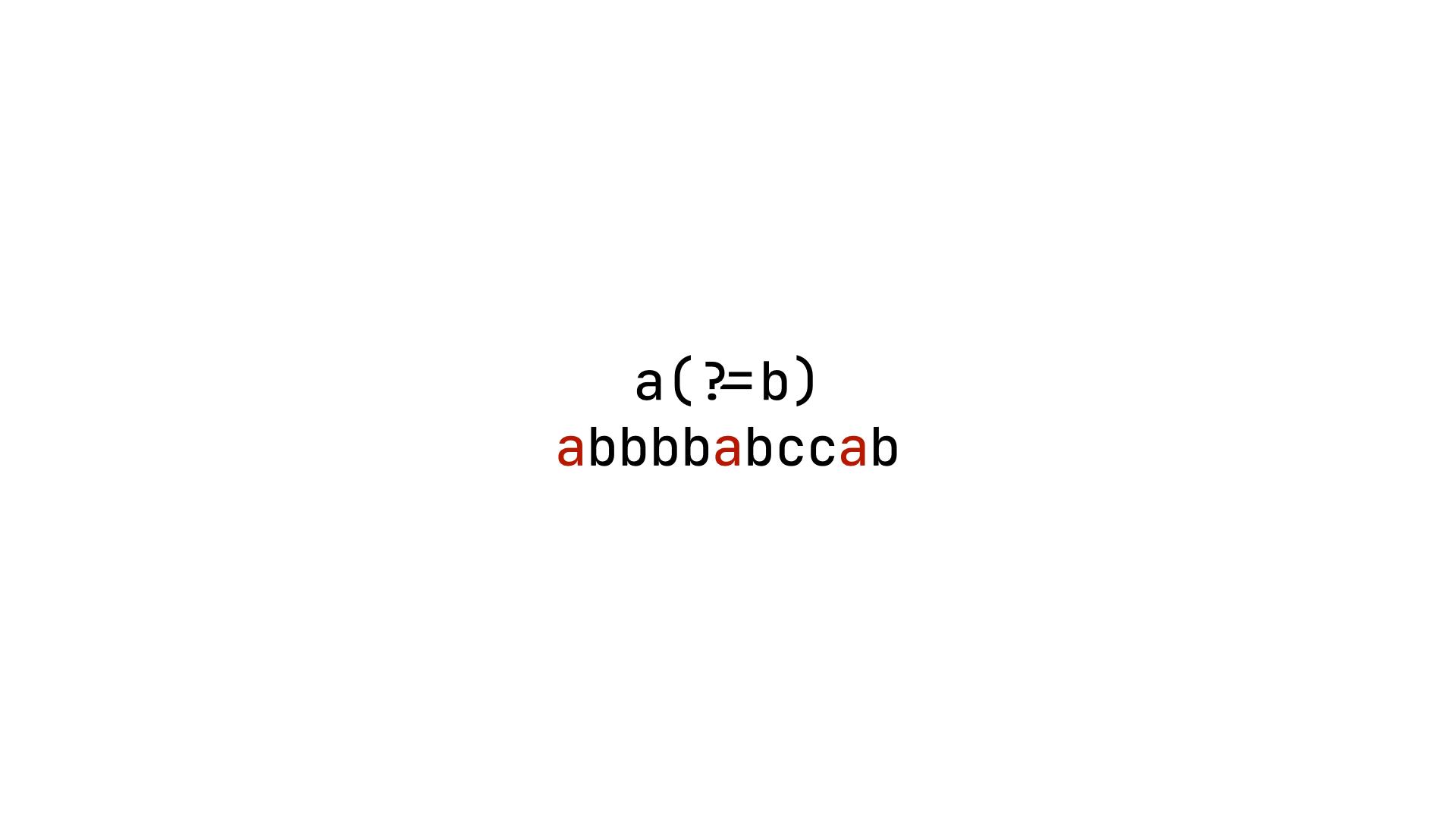
As shown in the above image, only a is matched in this regular expression.
Not just characters, the lookahead syntax can accept any valid regular expression. For example: ,(?=(?:\d{3})+$) means to match a , that is followed by a sequence of three digits, and occurs one or more times, right at the end.

Negative lookahead, represented by ?!, does the opposite. For example, a(?!b) indicates matching a when it is not followed by b.
It’s particularly important to remember that both positive and negative lookaheads are considered zero-length assertions. This means they do not match any characters themselves, resulting in a length of 0, similar to anchors. If you have (?=a) without any characters following it, the outcome would be:

You will notice that while there is a successful match, the match length is 0, occurring between words.
The initial regular expressions:
/\B(?=(\d{3})+$)/ and /(?=(\d{3})+$)/ are similar in meaning (with some minor differences). Why are they similar? We will introduce \b and \B shortly.
The Meaning of \b and \B
\b
In regular expressions, case sensitivity often indicates a negation, for example, \d matches digits, while \D matches non-digits. First, let’s understand what \b means, referencing the MDN documentation:
A word boundary matches the position where a word character is not followed or preceded by another word character. Note that a matched word boundary is not included in the match. In other words, the length of a matched word boundary is zero.
To comprehend how a word character is defined, we must first understand \w, which is defined as:
Includes letters, digits, and underscores, equivalent to
[A-Za-z0-9_].
Now that we know what \w is, let’s clarify the phrase word character is not followed or preceded by another word character. \b appears in the following cases, and to avoid confusion, we will refer to a word character as \w:
- At the beginning of a word character
- Between a word character and a non-word character
- At the end of a word character
Visual representation can help clarify:

Using the concept of word boundaries is essentially about the edges between words. It is essential to emphasize that if no other characters are added, \b itself performs a zero-width match, meaning the match length is always 0, which does not imply a lack of match.
Do not confuse it with scenarios where characters are present; for example, d\b matches the character d when it is followed by a word boundary. Here, the character d will be matched:

\B
\B represents the opposite, indicating non-word boundary positions. What are non-word boundary positions? The areas without arrows in the image above represent these.

How to Properly Parse Regular Expressions
Understanding regular expressions requires experience. However, having some foundational knowledge can be beneficial in development. A regular expression can be viewed as a state machine transition, for example, \d+ can be illustrated as follows:

Generally, additional initial states may need to be included (for instance, if a non-digit is input, it should not transition to state 0), but understanding the concept is sufficient. The arrows indicate possible input characters, determining whether to transition to the next state. If the state is an accepting state, it signifies a successful match.

Analyzing the Expressions
Method 1: Utilizing Zero-Length Matching
Now that we’ve covered the preliminary knowledge, we can finally start analyzing. First, let’s look at the first expression: /\B(?=(\d{3})+$)/g
The initial \B matches non-word boundary positions. Next, examining the expression following (?=), (\d{3})+ signifies matching one or more occurrences of three consecutive digits, such as 333, 666, 123, etc. Then, the expression following (?!), \d, represents matching a single digit. Overall, the expression means: match a non-word boundary (preceded by one digit that is not preceded by three consecutive digits).
What’s intriguing here is the (\d{3})+$) part, indicating that the matching result must be a multiple of three in length and must end precisely. For instance, 123456 is a multiple of three, while 12345, although it matches one \d{3}, does not count because it does not end correctly.
Using this feature along with clever application of \B, for the number 1000000, it will match two positions:

Thus, when calling .replace, it can be written as:
"1000000".replace(/\B(?=(\d{3})+$)/g, ",");Based on the matching results shown, commas will be inserted at these two positions, transforming it into 1,000,000. This is why this regular expression does not require $1, because both \B and (?=) are zero-length matches, resulting in a match length of 0.
The matching process can be observed in the video below. The number of matches can only be considered a reference, as it may vary based on the programming language, and some steps have been omitted, but the overall process looks something like this:
Method 2: Matching Numbers Where Commas Should Be Added
/(\d)(?=(\d{3})+$)/
From this, you can see that aside from removing \B and adding \d, the overall structure remains largely unchanged. However, one key difference is that \d will actually match digits. The final result will look like this:

(In the image, ?: is added to indicate that the matched result does not need to be placed into a group; the outcome remains the same.)
I personally prefer to use ?: for values that are grouped but not utilized, as it makes it easier for others and my future self to understand.
The overall process would look like this (with the unsuccessful matching processes omitted):
So in JavaScript, it can be written as:
"1000000".replace(/(\d)(?=(\d{3})+$)/g, "$1,"); // Note the $1 hereThis $1 is significant because we want to include the matched character as well; if only , is included, it would result in: ,00,000.
Additional Considerations and Approaches
Both regular expressions above use (?=(\d{3})+$) as the matching condition. However, in practice, decimal points may also occur, which would prevent a successful match for numbers like 1000.12.
In this case, you may need to modify the expression to appropriately handle the presence of decimal points, such as incorporating \b to establish a word boundary that allows matching to stop at the decimal point.
Additionally, the browser API supports Intl.NumberFormat, which is ready to use without waiting. More information can be found in the MDN documentation:
new Intl.NumberFormat('ja-JP', { style: 'currency', currency: 'JPY' }).format(number);Performance and Other Thoughts
Since the outcomes are the same, the remaining considerations boil down to readability and performance.
In terms of readability and usability, Intl.NumberFormat is undoubtedly the best option, with MDN’s documentation being clear and straightforward.
One point to keep in mind regarding performance is that using jsbench for testing shows that Intl.NumberFormat performs almost half as quickly. I suspect this is due to the overhead of loading i18n and converting numbers for various locales.

Moreover, zero-length matching is also about twice as fast compared to using \d. This is likely due to the properties of zero-length matches. However, it’s important to note that expressions like (\d{3})+, which include +, will utilize backtracking to match, meaning they will try to match the maximum possible results before backtracking. Excessive backtracking can lead to performance issues with regular expressions, so special care should be taken with such expressions.
In practice, we can use requestIdleCallback to delay the initialization of Intl.NumberFormat, minimizing its impact on performance. Alternatively, we could write a function to encapsulate the logic and initialize it only when truly called by other files. This should help avoid performance problems.
Other Approaches
The regular expressions mentioned above primarily rely on lookahead. What if we were to implement a loop ourselves? Here’s how I would rewrite /(\d)(?=(?:\d{3})+\b)/g:
let digits = number.toFixed(2).toString()
let matcher = /(\d)(?=(?:\d{3})+\b)/g
while (matcher.test(digits)) {
let first = digits.slice(0, matcher.lastIndex);
let second = digits.slice(matcher.lastIndex);
digits = first + "," + second
}And a more intuitive approach, modifying the number each time:
let digits = number.toFixed(2).toString()
let matcher = /(\d+)(\d{3})/
while (matcher.test(digits)) {
digits = digits.replace(matcher, "$1,$2");
}Let’s take another look at the results:
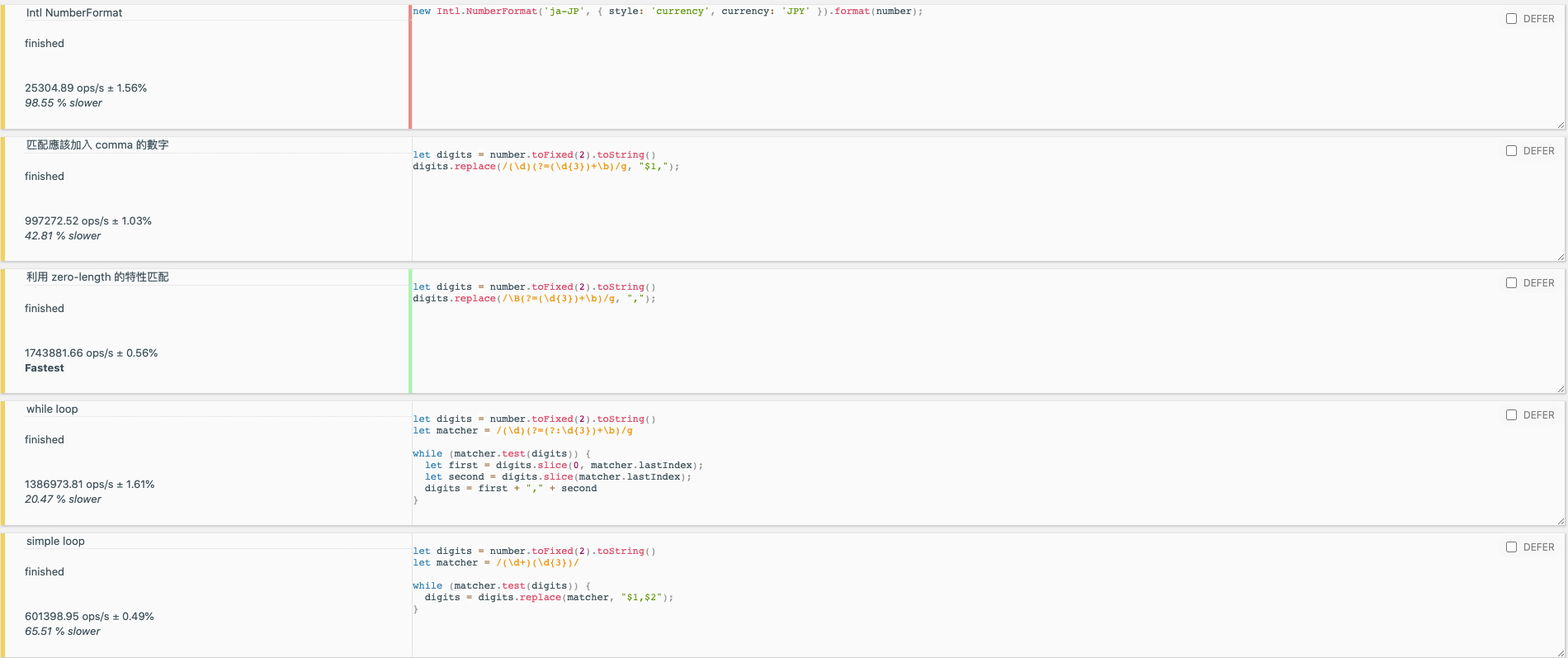
| Name | Ops/s | |
|---|---|---|
Zero-length /\B(?=(\d{3})+\b)/g | 1778943 ops/s fastest | |
| Zero-length matching (without \B) | 1712701 ops/s 3.72% slower | |
| while loop | 1371453 ops/s 22.91% slower | |
| simple loop | 597173.88 ops/s 66.43% slower | |
Intl.NumberFormat | 25304.89 ops/s 98.55% slower |
The fastest remains the zero-length matching approach, followed by the while-loop. The slowest is still Intl.NumberFormat. If you’re interested in the test results, feel free to check it out here.
Conclusion
There is much to discuss regarding regular expressions, and concepts like lookahead and word boundary are relatively underrepresented. This summary aims to clarify them. Many concepts are detailed in the MDN documentation, and you can visualize your regular expressions using Regex101, which also provides thorough explanations, making it very convenient.
However, I still believe that while regular expressions are useful, they can be quite challenging to read.
Related Resources
Related Posts
- CSS field-sizing — Auto-Resize Form Elements with One Line of CSSMaking a textarea auto-resize used to require JavaScript to watch scrollHeight. CSS field-sizing: content replaces all of that in one line, supporting textarea, input, and select.
- Make Your Hyperlink Underlines Look Better: text-underline-offsetBy default, underlines sit very close to the text, and some designers dislike this style. Personally, I don’t think it looks very good either.
- Why Web Design Shouldn’t Chase Pixel PerfectOnly pay attention to Pixel Perfect when it really matters; otherwise, it often leads to a lose-lose situation.
- Let’s Write Colors with CSS HSL! (And a Better Way)In web development, the traditional HEX and RGB color notations are widely used, but they are not very readable or intuitive, and their capabilities are limited in wider color spaces such as P3. HSL (Hue, Saturation, Lightness) provides a more intuitive way to define colors, making it easier for developers to understand and adjust them. By describing colors through the three dimensions of hue, saturation, and lightness, HSL makes color adjustment more human-friendly. In design systems in particular, HSL can better represent lightness variations in a color palette.