在一般顯示貨幣的時候通常會有一個需求,就是將原數字轉成人類比較好看懂的格式,例如:
- 1234567 → 1,234,567
- 10000 → 10,000
在前端當中我們可以用幾種方式達到:
- 透過
Intl.NumberFormat(老舊瀏覽器可能不支援,需要 polyfill) - 透過正規表達式加上
.replace
關於這個問題在 StackOverflow 上有相當多討論,其中最熱門的應該是這篇:How to print a number with commas as thousands separators in JavaScript
解答有許多種,但整體的形狀不外乎這兩個:
const reg1 = /\B(?=(\d{3})+$)/
const reg2 = /(\d)(?=(\d{3})+$)/這篇文章會試著闡述這兩個正規表達式的不同與實際執行的方式。最後會實際跑跑看效能。
前言
在開始之前,這裡有幾個比較重要的概念需要事先理解:positive lookahead、negative lookahead 以及 word boundary。這是一般在學習正規表達式時比較少碰到,但實際上相當強大的概念。
Positive lookahead 與 Negative Lookahead
在正規表達式當中,positive lookahead 的符號以 ?= 表示,假設以 a(?=b) 來解釋,這個正規表達式的意思是,匹配後一個字母為 b 的 a。在這邊要特別注意的是,?= 本身並不會匹配,也就說這個正規表達式只會匹配 a 而已。
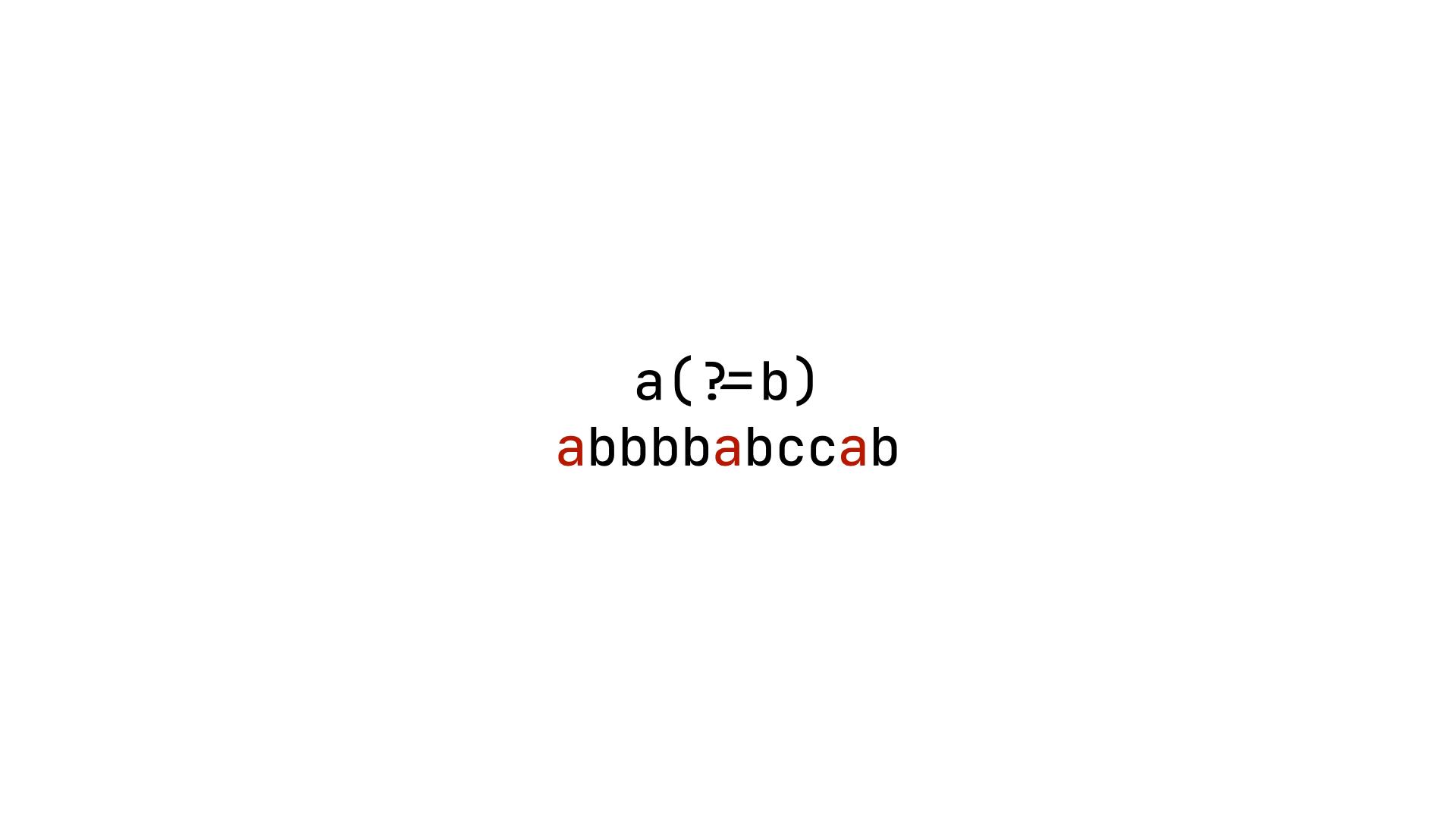
如上圖,上述的正規表達式中,只有 a 會被匹配。
不只是字元,lookahead 的語法也可以接受任意合法的正規表達式。例如:,(?=(?:\d{3})+$),這個正規表達式的意思是,匹配後面是連續 3 個數字,並且匹配 1 至多次,且剛好為結尾的 ,

negative lookahead,符號以 ?! 表示,跟 positive 相反,假設以 a(?!b),代表匹配後一個字母不為 b 的 a。
需要特別注意的是,positive lookahead 與 negative lookahead 都是屬於 zero-length 的表達式,也就是說他們本身並不匹配任何字元,所以本身的長度會是 0,有點類似錨點的感覺。假設你在 (?=a) 沒有加上任何字元,那麼這會是執行的結果:

你會發現雖然有成功匹配,但匹配的長度是 0,在字與字之間。
在開頭的正規表達式:
/\B(?=(\d{3})+$)/ 跟 /(?=(\d{3})+$)/ 意思是雷同的(還是有些地方不同)。為什麼兩個表達式是雷同的呢?我們下面會介紹 \b 與 \B
\b 與 \B 的意思
\b
正規表達式當中的大小寫,通常都代表著正反向的意思,例如 \d 代表的是匹配數字,那麼 \D 就代表匹配不是數字。所以首先我們先來理解 \b 是什麼意思,參考了 MDN 當中的文件:
A word boundary matches the position where a word character is not followed or preceded by another word-character. Note that a matched word boundary is not included in the match. In other words, the length of a matched word boundary is zero.
另外,要理解 word character 是如何被定義的,還要先理解 \w,\w 是這樣定義的:
包含數字字母與底線,等同於
[A-Za-z0-9_]。
知道 \w 是什麼了之後,我們來看看句中的 word character is not followed or preceded by another word-character 是什麼意思, \b 會出現在以下幾種情況,為了避免混肴,我們一律使用 word character 代表 \w
- word character 的開頭
- word character 與非 word character 之間
- word character 的結尾
直接看圖應該會比較清楚:

其實用 word boundary 的概念去理解也可以,就是字和字邊邊的地方。還是要特別強調,如果沒有加入其他字元的話,\b 本身是無寬度匹配的,所以匹配的長度都是 0,但不代表沒有匹配。
也不要跟有字元的時候搞混,例如 d\b,這個意思是匹配字元 d 後面為 word boundary 的字母 d。這時候就會實際匹配的字元 d 了:

\B
\B 取反向之意,就是非 word boundary 的地方。什麼是非 word bounary 的地方呢?上圖沒有標上箭頭就是了。

如何正確解析正規表達式
正規表達式要看得懂,本來就需要經驗累積。不過在開發上使用到的東西,還是有點觀念會比較好。一個正規表達式可以被看成狀態機的轉換,例如 \d+,我們就可以這樣寫:

一般來說可能要再加上初始狀態(例如如果輸入非數字的話,就不應該到 0 這個狀態),但只要看得懂就好。在箭頭中放上可能的輸入文字,並且判斷是否跳入下一個狀態,如果狀態是終止狀態,代表接受本次的匹配。

開始解析表達式
方法 1:利用 zero-length 的特性匹配
把前情提要以及要具備的知識講解完之後,我們終於可以開始分析了,首先讓我們來看一下第一個:/\B(?=(\d{3})+$)/g
開頭的 \B 是匹配非 word boundary 的位置,接下來看 (?=) 後的正規表達式,(\d{3})+ 代表匹配一次或多次連續 3 個數字,像是 333, 666, 123 等等。接下來看的 (?!) 後的正規表達式,\d 代表匹配一個數字。把整串的意思連在一起就是:匹配( 1 個數字前不為 3 個連續的數字且匹配 1 次到多次)的非 word boundary
在這邊,比較好玩地方在於後面的 (\d{3})+$),這個正規表達式的意思是匹配的結果長度一定會是 3 的倍數而且要剛好結尾。像是:123456 長度是 3 的倍數,但 12345 雖然有匹配一個 \d{3} 但因為不是結尾因此不算匹配。
利用這樣的特性,加上 \B 的巧妙應用,以數字 1000000 來說最後會匹配出兩個位置

所以在呼叫 .replace 的時候可以這樣寫:
"1000000".replace(/\B(?=(\d{3})+$)/g, ",");根據上圖的匹配結果,會在這兩個位置當中插入, 變成 1,000,000。這也是為什麼這個正規表達式不需要透過 $1, 的原因,因為 \B 以及 (?=) 都是 zero-length match,所以匹配長度會是 0。
匹配過程可以透過下面的影片來觀察,這邊的匹配次數只能當參考,根據語言不同可能會有不同狀況,同時也有省略一些步驟,但大致上的流程大概像這樣:
方法 2:匹配應該加入 comma 的數字
/(\d)(?=(\d{3})+$)/
從這邊你可以發現,除了 \B 被拿掉然後加入 \d 之外,整體上並沒有差很多。不過在這邊有一個地方不同,就是 \d 是會實際匹配數字的。最後的結果會像這樣:

(圖片中加入了 ?: 來表示不用將匹配結果放到 group 裡面,結果是一樣的)
我自己是會習慣如果被 group 住的值不會拿來用,就用 ?: 表示,比較容易讓其他人和未來的自己讀懂。
整體的過程大概會像這樣:(省略中間匹配失敗的過程)
所以在 JavaScript 當中會這樣寫:
"1000000".replace(/(\d)(?=(\d{3})+$)/g, "$1,"); // 注意這邊的 $1這邊的 $1 很重要,因為我們要把匹配的字元也一起放進去,只有 , 的話會像這樣:,00,000。
其他考量與方式
上述的兩個正規表達式當中都是以 (?=(\d{3})+$) 當作匹配的條件,不過在實務上,有時候也會出現小數點,這樣一來像是 1000.12 就沒辦法成功匹配。
這時可能需要修改表達式,來處理小數點出現的情況,例如加入 \b 來做 word boundary 讓匹配可以停在小數點上。
另外,瀏覽器的 API 有支援 Intl.NumberFormat,開箱即用不用等。使用的方式可參考 MDN 文件
new Intl.NumberFormat('ja-JP', { style: 'currency', currency: 'JPY' }).format(number);效能與其他想法
既然結果都相同,那麼要考量的點剩下幾個:易讀性與效能。
從易讀、易用性上來說,最好的當然是 Intl.NumberFormat,MDN 手把手的文件寫得清清楚楚,非常好用。
唯一要注意的是效能部分,這邊使用 jsbench 做測試。可以看到 Intl.NumberFormat 效能慢了幾乎一倍。我猜是載入 i18n 跟各國數字轉換需要比較大的空間?

另外用 zero-length 匹配也比用 \d 匹配快了一半,我想是因為 zero-length 的特性?不過在這裡要注意的是,像是 (\d{3})+ 這類型的表達式,只要有 + 都會用 backtracking 的方式做匹配,也就是盡可能匹配最多的結果。所以像是 .+123之類的表達式,他會盡可能地匹配多一點的結果,直到匹配不成功在往前回溯。大量的 backtracking 會造成正規表達式的效能問題,所以在用類似的表達式時要特別注意。
實務上,我們可以利用 requestIdleCallback 的方式,讓 Intl.NumberFormat 的初始化延遲載入,避免過度影響效能,或者是額外寫函數將邏輯包起來,真的被其他檔案呼叫之後再做初始化也可以。這樣應該可以避免效能問題。
其他方式
上述的正規表達式主要建立在 lookahead 之上,如果我們自己跑迴圈做的話可以怎麼做?這邊我把 /(\d)(?=(?:\d{3})+\b)/g 改寫為:
let digits = number.toFixed(2).toString()
let matcher = /(\d)(?=(?:\d{3})+\b)/g
while (matcher.test(digits)) {
let first = digits.slice(0, matcher.lastIndex);
let second = digits.slice(matcher.lastIndex);
digits = first + "," + second
}以及更直覺的方式,每跑一次改一次:
let digits = number.toFixed(2).toString()
let matcher = /(\d+)(\d{3})/
while (matcher.test(digits)) {
digits = digits.replace(matcher, "$1,$2");
}我們再來看一次結果:
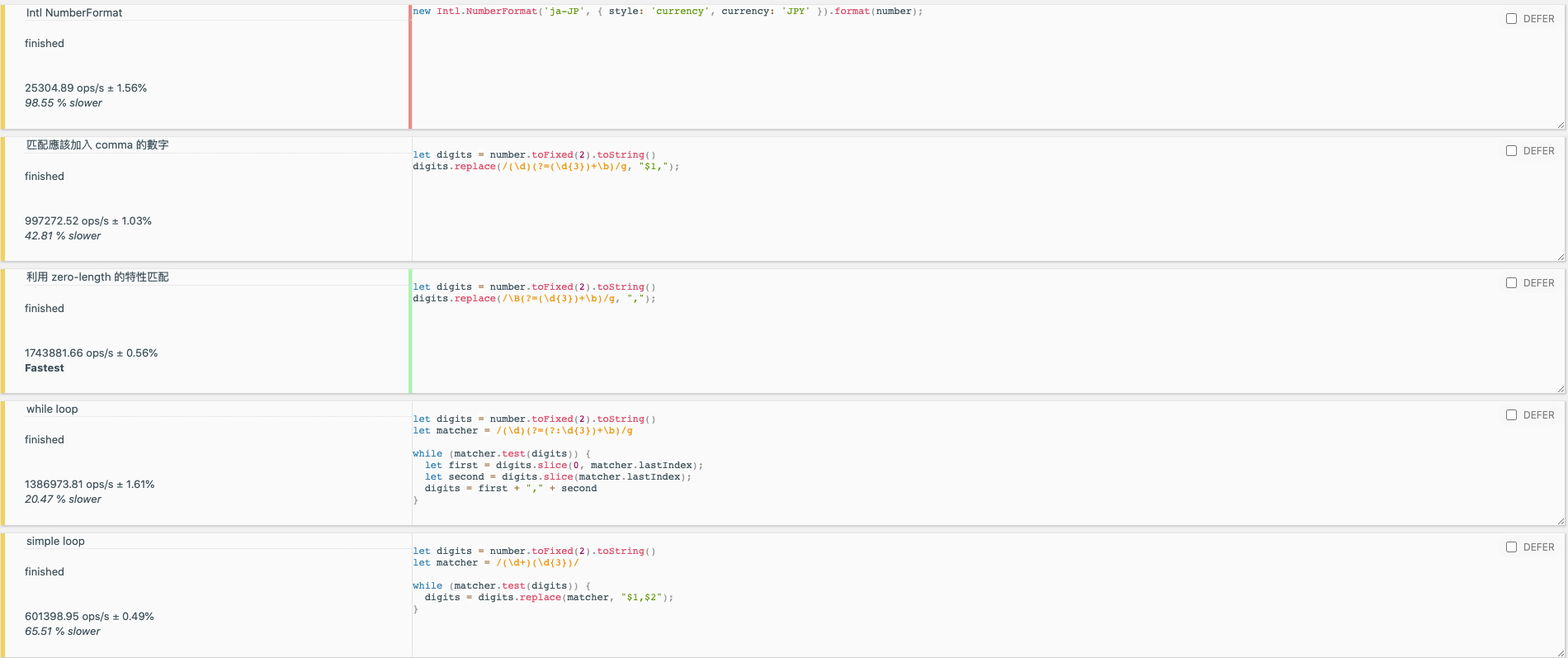
| Name | Ops/s | |
|---|---|---|
Zero-length /\B(?=(\d{3})+\b)/g | 1778943 ops/s fastest | |
| 利用 zero-length 的特性匹配 (without \B) | 1712701 ops/s 3.72% slower | |
| while loop | 1371453 ops/s 22.91% slower | |
| simple loop | 597173.88 ops/s 66.43% slower | |
Intl.NumberFormat | 25304.89 ops/s 98.55% slower |
最快的一樣是 zero-length 做匹配的方式,再來才是 while-loop,最慢的還是 Intl.NumberFormat。如果對測試結果有興趣的話,可以到連結當中試試看。
後記
一個正規表達式可以講的東西很多,lookahead 以及 word boundary 是相對比較少提起的概念,在這邊整理一次。有很多概念在 MDN 文件上都有詳細敘述,透過 Regex101 這個網站可以視覺化你的正規表達式,旁邊還有詳細說明非常方便。
不過我還是覺得正規表達式雖然方便好用,但真的很難看懂啊。
