
質問やフィードバックがありましたら、フォームからお願いします
本文は台湾華語で、ChatGPT で翻訳している記事なので、不確かな部分や間違いがあるかもしれません。ご了承ください
遞帰下降は直感的で強力な解析手法と言えます。
今日は、JSONを解析するところから始めて、ゼロからJSONパーサーを作成する方法を解説します。JSONの構造はシンプルで、練習には最適です。解析文法という作業は、フロントエンドや通常の開発とはあまり関係がないように思えますが、将来的にDSLを設計したり、特別な要件でカスタム言語を構築したりする場合に、これらの技術が役立つこともあります。
なぜ遞帰下降を学ぶべきか?
JSON.parseがあるのに、なぜ遞帰下降を学ぶ必要があるのでしょうか?簡単な文法解析を通じて、JSONデータを正常に解析するだけでなく、自分自身の文法を実装することもできます。また、この技術を他の場所にも応用することができます。
例えば、通常のJSONは以下のようになります:
{
"name": "kalan",
"age": 20
}もし新しい文法を追加するとしたら、「テンプレート」と呼びましょう。{}で囲まれた文字列は、自動的に変数で置き換えられます。例えば:
{
"name": "kalan",
"age": 20,
"job": $job$
}カスタマイズされたparse関数を使って解析すると:
parse(json, { job: 'engineer' });
// {
// "name": kalan,
// "age": 20,
// "job": "engineer"
// }または、新しい記号に変更したい場合:
{
"name" @ "kalan"
"age" @ 20
}今日は、JSONを解析できる遞帰下降パーサーを作成し、上記の2つの機能を追加していきます。
遞帰下降(Recursive Descent)とは?
遞帰下降について話すとき、LL、LR、トップダウン、非終端などの恐ろしい用語や記号に悩まされることがありますが、最も直感的な方法で話してみましょう。まず、図を見てみましょう:
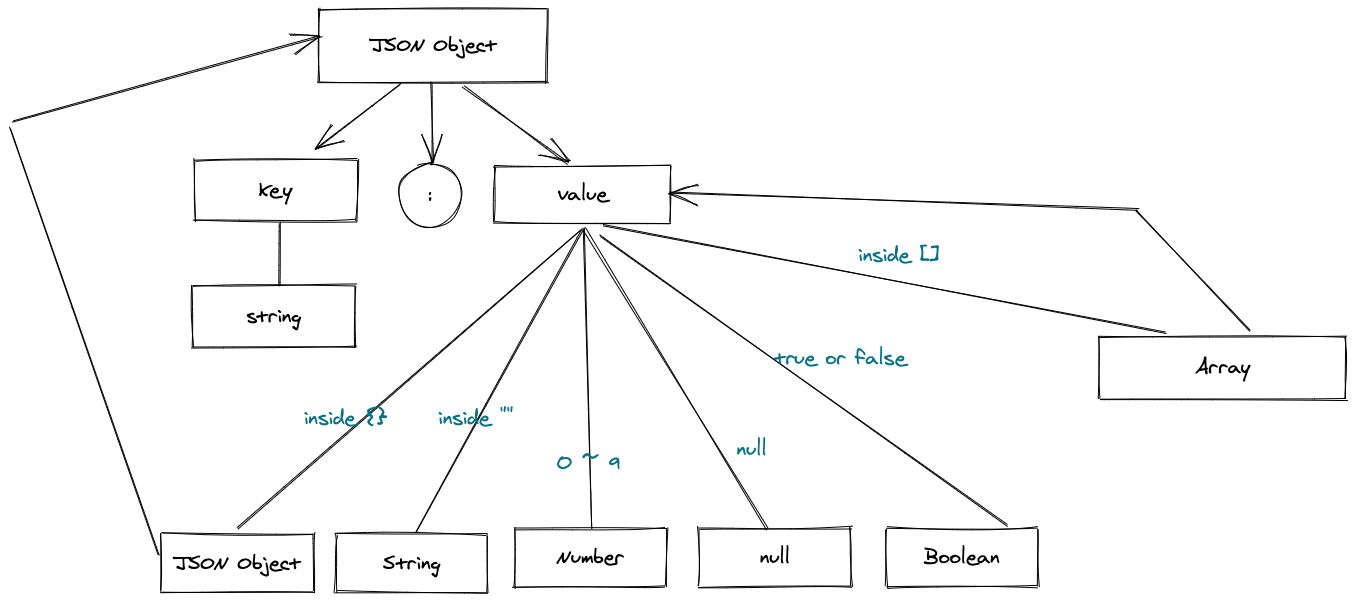
JSONの形式を図で表すと、JSONは主にkey + : + valueで構成されていることがわかります。valueはさらに文字列、ブール値、数値、null、objectなどに分解できます。
もしvalueがobjectであれば、同じルールを再適用できることに気づきます。つまり、図の最上部に戻り、同じルールで解析を続けるということです。
このように、無限にループすることを「遞帰」と呼び、上から下へルールを照合することを「トップダウン」と呼び、全体を組み合わせたものが「遞帰下降」です。
各型および文法の詳細定義については、JSON規範を参照できます:
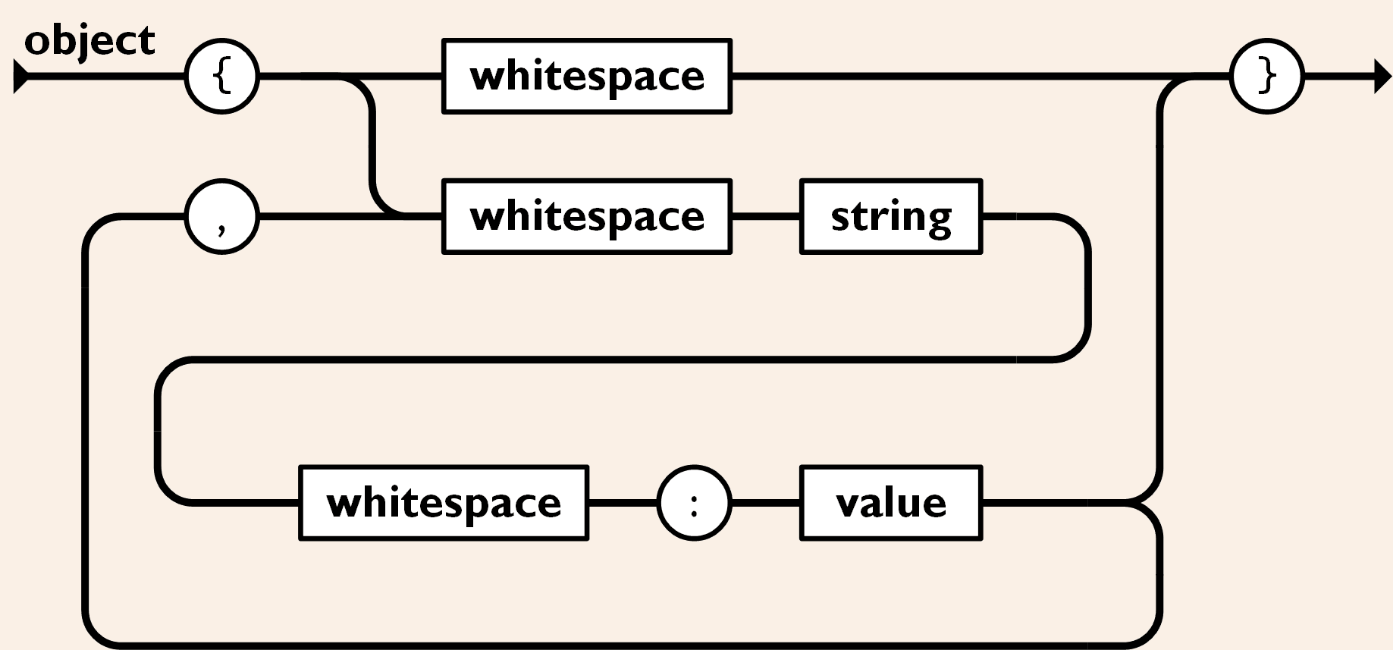
最もシンプルな例から始めましょう:キーと値が1つだけあり、値は文字列型です。
{
"name": "kalan"
}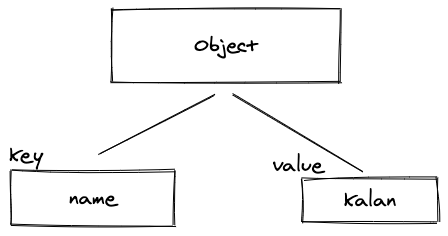
以下のプロセス(上記の図を参照)で進めます。
{に出会ったら、オブジェクト解析を開始します。key解析に入ります。期待されるのは文字列です。"に出会ったら、文字列解析に入ります。- n, a, m, eに出会ったら、nameをキーとして扱います。
"に出会ったら、文字列マッチングを終了し、:が来ることを期待します。:に出会ったら、value解析に入ります。"に出会ったら、文字列解析に入ります。- k, a, l, a, nに出会ったら、値を
kalanに設定します。 "に出会ったら、文字列マッチングを終了します。}に出会ったら、オブジェクトマッチングを終了します。- 空文字列(EOF)に出会ったら、解析を終了します。
このプロセスからわかるように、解析のプロセスは一連の状態変化に似ています。マッチする値に出会うたびに、上記の図のルールに従って、次のボックスに進むべきかをテストします。各ボックスで受け入れられる値は異なります。左から右にスムーズに進むことができれば、成功したことになります。
次に、実装を試みてみましょう。
シンプルなパーサーの実装
シンプルなパーサーは、ポインタ、位置情報、現在読み取っている文字の数を使って達成できます。
parse関数をエントリーポイントとして、特定の状態に合致したら対応する関数を実行します。
まず、使用する関数を定義しましょう:
class Parser {
constructor(raw) {
this.raw = raw;
this.index = 0;
}
// 現在の文字
current() {
return this.raw[this.index];
}
// 次の文字列が str と一致するかをチェック
// 例: next('{')
// 次の文字が '{' であるかを判別
// もしそうなら index を進めて
// true を返す
// 状態の判別に便利
next(str) {
if (this.raw.slice(this.index, this.index + str.length) === str) {
this.index += str.length;
return true;
}
return false;
}
// 空白をスキップする。現在は " " のみを考慮
// タブなどの機能は実装しない
skip() {
while (this.raw[this.index] <= " ") {
this.index += 1;
}
}
parse() {
const value = object(this); // エントリーポイント
return value;
}
}主要なエントリーポイントはparseを見てください。同時に、現在の状態を確認するために便利な補助関数skipとnextを定義しました。次に、object関数の実装を見てみましょう:
function object(parser) {
const obj = Object.create(null);
let key = "";
// もし { で始まるなら、object関数で解析する
if (parser.current() === "{") {
parser.next("{");
parser.skip();
// すぐに } に出会った場合
// 空のオブジェクト {}
if (parser.current() === "}") {
parser.next("}");
return obj;
}
// 現在の文字を読み取り、どの関数を使用して解析するかを判断
while (parser.current()) {
key = string(parser); // keyは必ず文字列であるため、文字列解析を使用
parser.skip(); // 空白文字をスキップ
parser.next(":"); // 期待されるのは :
obj[key] = string(parser); // 値は一律文字列と仮定し、文字列解析を使用
parser.skip();
if (parser.current() === "}") { // } に出会ったら、オブジェクト解析が終了したことを示し、objを返す
parser.next("}");
return obj;
}
parser.next(","); // もしカンマがあれば、次のkey-valueがあることを示し、whileで解析を続ける
parser.skip();
}
}
}-
現在の文字が
{なら- 次の文字が
}なら、空のオブジェクトであるため、返して終了します。
- 次の文字が
-
whileループに入って、
stringを使用してkeyを解析します(JSONのkeyは必ず文字列だからです)。string関数の実装は後で説明します。- 空白文字をスキップします(以下のような状況)
{ "name" : "value" }- 期待されるのは
:です。 - 値を
stringで解析します(ここでは一時的に文字列のみと仮定し、後で他の型の処理を追加します)。 - 空白文字をスキップします。
}に出会ったらオブジェクトの終わりを示し、objを返します。,に出会ったら、次のkey-valueを解析する必要があることを示します。- 空白文字をスキップします。
文字列解析の実装:
function string(parser) {
parser.next('"'); // 次の文字が " の場合、stringの方法で解析します。
if (parser.next('"')) {
// { "": "value" } 空のキーを持つJSONは不正と見なします。
throw new Error("JSON key is empty.");
}
let key = "";
let curr = "";
// " に出会うまで次の文字を読み続けます。
while (((curr = parser.current()), curr)) {
if (parser.next('"')) {
parser.index += 1;
return key;
}
key += curr;
parser.index += 1;
}
}- 期待される文字は
"です。 - 次の文字が
"である場合は空文字列を意味し、不正なキーとして警告を出します。 "に出会うまでwhileループに入ります。
練習したい場合は、Repoを参照してください。
手書きのパーサーは少し面倒なこともありますが、時には小さな状況が処理されないことがあります。練習する際は、最初からテストを書くことをお勧めします。そうすることで、手動テストの時間を大幅に節約できます。
結論
私たちは遞帰下降パーサーを実装しましたが、AST(抽象構文木)への変換プロセスを経ずに、直接JavaScriptのオブジェクトに変換しました。これは、JSONのデータ構造が比較的シンプルで、この変換が不要だからです。
また、パーサーを実装する際には、いくつかの視点を考慮することをお勧めします:
- エラーメッセージをより親切にするために、情報を一次元ではなく、行と列の二次元で記録することを考えてみましょう。
- より親切なエラーメッセージを実装すること、例えば
}を忘れた場合に開発者に警告したり、文法エラーの際に明確に誤りの場所を指摘したりすることです。
柔軟性を保つために、記号を変数(トークン)に置き換えることもできます。
part2では、数値、配列、ブール値、nullなどの他の型を実装し、より完全なJSONパーサーを作成します。同時に、先ほど説明した2つのカスタマイズ機能、@を区切りとして使用し、{}をテンプレートとして使用する機能も実装していきます。
この記事が役に立ったと思ったら、下のリンクからコーヒーを奢ってくれると嬉しいです ☕ 私の普通の一日が輝かしいものになります ✨
☕Buy me a coffee